
Published on December 20, 2023 by Rishabh Kumar
Importance of Alternative data in investment decisions
Unlike traditional credit data, alternative data encompasses of broader spectrum of information. For this reason, lenders today are increasingly turning to alternative datasets to make more informed decisions, including utility payment history and bank transaction data. Moreover, lenders can incorporate alternative data for better risk management, expanded lending opportunities, and informed decision-making.
Integrating alternative data into decision-making processes helps to provide real-time granular insights into various companies or markets. It offers unique perspectives that traditional financial statements may not provide. However, to ensure responsible use, lenders should implement rigorous standards and practices to ensure alternative data for investors is fair and transparent. This is crucial for inclusive and equitable financial systems.
Financial services technology consulting provides initiatives to enable lenders to have access to broader information, enable their abilities to assess credit risk accurately, and drive innovation. Investors can identify emerging trends and patterns before they become apparent in traditional financial reports. This allows more accurate forecasting and timely informed investment decisions.
Why Investors Need to Consider Alternative Datasets
Investors are keen to boost their returns. In search of returns, data analytics acts as a weapon of choice for capturing the captivating advantage. Investment managers can utilise useful insights from alternative data to gain additional business insights.
Today, investors are getting access to more alternative data and more information. Numerous alternative data sources uncover hidden patterns and emerging trends that traditional data may miss. Therefore, incorporating alternative data investment management can improve the accuracy of predictions and forecasts, provide early warning signals of potential risks, and monitor data. In a highly competitive landscape, access to unique and timely data can provide a significant advantage.
Alternative data (alt data) is now more widely available, and traditional financial data organisations that do not institutionalise its use run the risk of making less informed decisions than their data-centric competitors. The use of alt data sources is becoming more and more essential for success in the dynamic world of investment management. This blog covers the strategies organisations could follow to evaluate and integrate alternative data for investment decisions.
If your firm is looking to leverage financial services technology consulting for better decision-making, evaluating the right alternative data becomes crucial.
Evaluating alternative datasets:
Investment management firms looking to employ alternative datasets for investment research must assess their value and risks after setting out objectives for their use such as the value they generate for their investment strategy and before integrating them into their investment strategy. The data vendor plays a critical role in helping organisations evaluate alternative data for investment decisions.
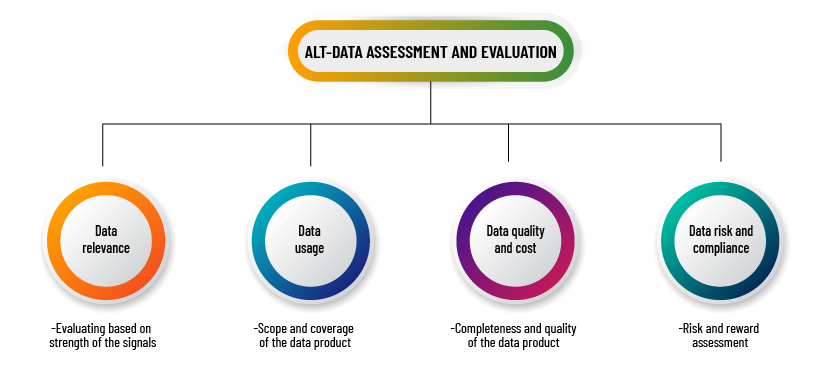
Factors to Consider While Evaluating Alternative datasets:
-
Evaluating based on strength of signals:
The data vendor should be able to provide a quantitative assessment, which could be in the form of white papers, with case studies showing how the signal could be used to generate alpha. For example, a research paper providing correlation and statistical analysis of the features of the alternative dataset (whether raw or transformed) and the organisation’s operating metrics such as total revenue or net profit. Based on this information, the organisation could decide whether to purchase the data for testing.
-
Scope and coverage of the data product:
Large investment management firms such as quant hedge funds would look for datasets that can be used in trading for multiple companies. An ideal alternative dataset should cover companies from all sectors, but most often than not, it tends to be sector-specific. For example, patent data is mostly available for healthcare companies, and transactional data for companies in the consumer discretionary sector. Industry-specific datasets could be preferable, especially if they provide high alpha for a single security, as the organisation would be able to allocate capital and manage risks efficiently.
-
Completeness and quality of the data product:
Data vendors that provide metrics relating to the quality and completeness of their data product can make it easy for the organisation to decide whether to integrate them into their investment strategy or not. For example, in the case of an aggregated data product, metrics relating to the robustness and accuracy of ticker tagging, debiasing and panelling processes in R&D. On the investment management firm’s side, it means estimating the effort required to conduct a robust data validation and testing process and, based on that, deciding whether to make the purchase.
-
Risk-reward assessment:
The information advantage that alternative datasets provide, facilitating outperformance of benchmarks, is no doubt the main reward. However, the organisation needs to keep in mind that trading signals may be lost over time due to alpha decay. The organisation should also conduct due diligence to assess the following risks before purchasing the data: (1) legal risks – does the dataset comply with governance and regulatory rules? For example, does the dataset comply with the EU’s GDPR and the US’s CFPB regulations, and is private information such as PII being properly anonymised? (2) Business risks – what if the data vendor ceases activity after its services are subscribed to?
In the context of the data management value chain, these preliminary evaluation points fall under the following parts of the data assessment spectrum:
How to Integrate Alternative Datasets:
After deciding to purchase an alternative dataset, the investment management firm could prepare to integrate it into its investment process, following the steps listed below:
1. Testing the dataset:
At this stage, the organisation should pre-assess the existence of signals in the sample of the dataset by running a proof-of-concept test to determine whether it is consistent with the expected performance. This is done after signing up for a trial agreement with the vendor. Also, through this testing, the organisation may be able to estimate the return on investment (ROI) qualitatively and make decisions regarding feature selection and collection. ROI can be represented as the trade-off between potential payout and the cost incurred for data collection and processing. A simple equation may be as follows:
ROI = Payout potential - Data collection and processing cost
where,
-
Payout potential represents the expected gain in terms of alpha generation or any other performance benchmark.
-
Data collection and processing cost represents the total cost associated with acquisition, cleaning, processing and storing the dataset.
Additionally, this calculation should consider the time frame within which the benefits will be realised along with any other uncertainties in the estimates. The focus should be on maximising the payout while keeping costs within a reasonable limit. Therefore, collaboration between business experts, domain experts and data scientists is crucial for making informed decisions on which data features are to be collected and for balancing cost considerations with expected benefits.
2. Ingesting the data:
If the dataset passes the trial, the organisation can purchase the production licence for the dataset and decide how to import and store the data. For higher-frequency data feeds, the organisation’s data engineers can develop wrappers for the APIs provided by the vendor to import them in real time. In the case of low-frequency data feeds, such as weekly or daily feeds, the data engineers may be able to process flat file feeds in XML, CSV or parquet formats on a batch basis. In the case of unstructured data, some pre-processing and transformation may need be conducted to blend structured and unstructured data in line with the organisation’s infrastructure. The target storage layer for the dataset would depend on its property; for example, a structured dataset would be best suited for an SQL database, and a link-based dataset would be best suited for a graph database.
3. Preparing the data:
This involves multiple steps such as data collection to identify relevant fields depending on the use case, data cleaning to ensure the reference variables are common across other tables and data normalisation to eliminate redundant data and establish relationships across the tables. All this is done to make the dataset compatible with existing or new machine-learning models further down the line, especially if it involves data from traditional datasets stored in other tables.
4. Extracting signals and modelling:
The organisation may be looking for buy/sell signals or forecasts that can be used as input for the trading process, or in the case of risk management, it may involve volatility forecasts for exiting certain markets/assets. Based on the defined objectives and use case, brainstorming sessions are conducted to scale up the signal extraction process for constructing a testable hypothesis, based on which data scientists can decide on an appropriate strategy for modelling. This process involves business analysts and experts in data and market trends. The extracted signals are then back-tested against historical data and evaluated against success criteria such as average alpha generated by the signals over a period of time. If the signals pass the success criteria, they are implemented for production in a live environment.
5. Reporting, dashboarding and monitoring:
The organisation can now decide on reporting and dashboarding infrastructure. For example, deciding on the digital UI/UX for the reporting application so that business leaders/decision makers can obtain insights clearly. The organisation should also develop a process to adapt the integration strategy in the event the data source changes. Performance and data quality should be continuously monitored and adjustments made to reflect the changes in the environment in which the organisation operates.
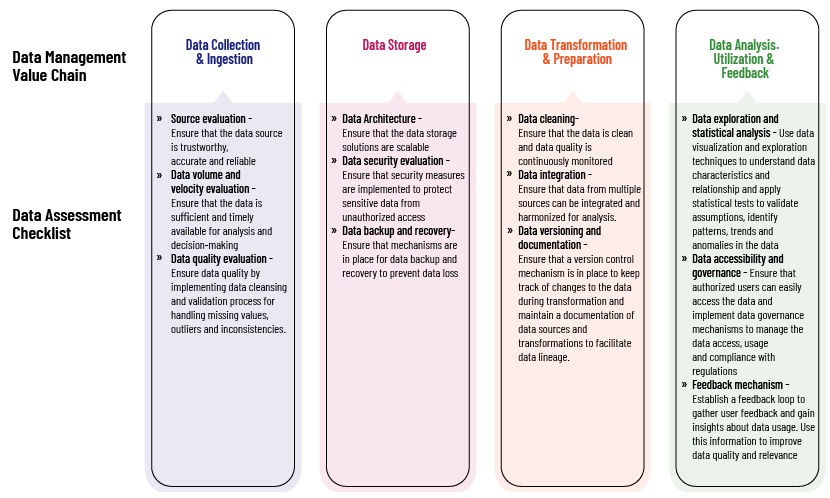
Data assessment and evaluation as sub-processes of the data management value chain and integration stages:
Data assessment and evaluation is not limited to being a standalone preliminary stage; instead, it is an ongoing process that occurs at every stage of the data management value chain and integration stages. The following is a summarised checklist against each stage of the data management value chain
It is not easy to incorporate alternative data into the process of making financial decisions. Creating a thorough, organised plan with clear actions to maximise the potential of alternative data for investment decisions would be essential for success.
How Acuity Knowledge Partners can help
One of the challenges facing investment management firms is handling data management and governance. Our team of experts in data and related technologies provides optimal and efficient solutions for data management and governance. We also help clients at the various stages of the data integration lifecycle, such as collection, cleaning and analysis of data from several different sources, enabling them to make well-informed, data-driven decisions.
References:
-
The Risk-Reducing Stages of Alternative Data Implementation (garp.org)
-
Harnessing Alternative Data for Competitive Advantage | California Management Review (berkeley.edu)
-
The Book of Alternative Data: A Guide for Investors, Traders and Risk Managers by Alexander Denev, Saeed Amen
What's your view?

Thank you for sharing your Comments
Share this on


About the Author

Rishabh have over 2 years of experience working with alternative data as a data analyst using Spark on Databricks along with Python, Pyspark and SQL. He holds a bachelor’s degree in Software Engineering from Delhi Technological University.
 Blog
Blog
Decoding wall-crossing....
Key terms The term “wall-crossing” stems from the phrase “Chinese wall”, widely u....Read More
 Blog
Blog
Future flow securitisations – novel balance sh....
Navigating the world of structured finance management solutions Structured finance is a f....Read More
 Blog
Blog
Product marketing data specialists in asset mana....
In the fast-paced world of asset management, where precision and timeliness are paramount,....Read More
Like the way we think?
Next time we post something new, we'll send it to your inbox