
Published on June 30, 2021 by Surbhi Badalia
Most data science models used in the financial disciplines of credit risk, fraud, capital markets and other businesses, still use traditional regression models such as generalised linear or logistic regression because of their interpretability for decision makers. However, these traditional models are limited by their performance and accuracy levels and may generate lower business impact than expected. Machine learning (ML) algorithms have been gaining popularity because of their high performance; however, they are limited by their interpretability, especially within financial services. In this blog, we explore ways to minimise the trade-off gap between model performance and interpretability.
Traditional methods of statistical learning and ML help us study input data and draw conclusions and make predictions. We input labelled data into a model for it to ‘learn’ the relationships between the features and target variables. Once a model ‘learns’ from the trained labelled data, it can then make predictions on a new set of features.
For example, if we want to know whether a borrower will default on his/her loan or not, we need to assess the borrower’s credit score, income statement, age and other details. It is time consuming and laborious to perform this task manually. However, if we use statistical models for this, the models would help draw conclusions based on past data patterns; we can then arrive at a decision much faster.
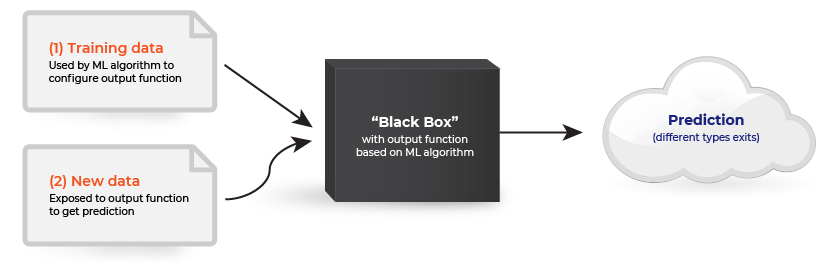
Once we train our model, we can provide a new set of data as an input and get an output prediction. Based on these input-output relationships, models are generally classified into two categories:
1) the white-box or traditional model: users can clearly identify internal workings—how the algorithm behaves, how it reaches conclusions, and the variables responsible for arriving at the conclusions. Traditional models have relatively lower performance but higher explainability. Some of the most frequently used models include linear regression and the decision tree.
2) the black-box or ML model: relative to white-box models, ML models lack clarity in their internal working components, but provide improved performance. An overview of the model flow is provided below. e.g., boosted/random forest models and deep learning models.
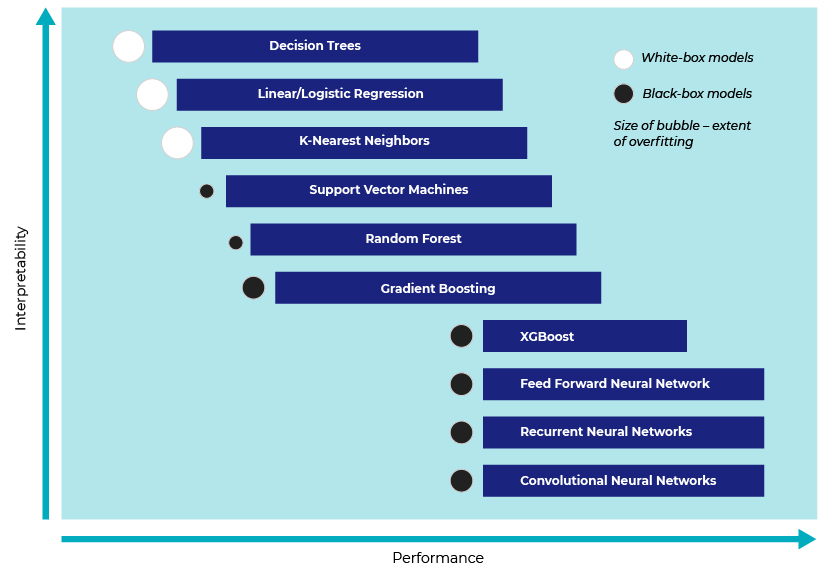
The following graph shows that advanced algorithms, such as Support Vector Machines (SVMs) and Artificial Neural Networks (ANNs) have better performance, but their prediction outcomes are tougher to interpret and explain.
To optimise the trade-off between accuracy and explainability, we can use a few interpretable techniques that would help resolve black-box explainability issues. Before we delve further into different interpretable techniques, let us understand the qualities of an interpretable algorithm:
Provides qualitative understanding between input and output, i.e. how changes in values of one variable impacts the others
Provides an explanation of a local instance prediction, i.e. local fidelity, rather than explaining the predictions only at a global level (global fidelity)
It is model agnostic i.e. the explainability can be applied to any model, including Random Forest (RF), Gradient Boosting Machine (GBM), ANN and SVM
The illustration below shows how such interpretable techniques explain predictions where one wants to know if the credit decision for a loan application would be approval or rejection.
Figure 1 includes prediction input data and the loan values for which we need to make approval decisions.
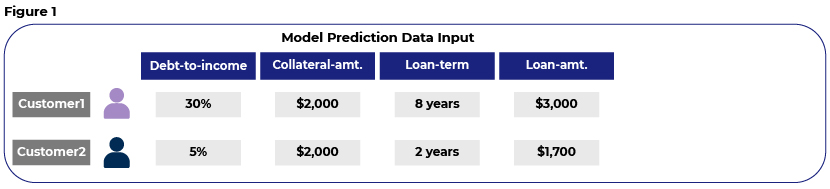
Figure 2 details the interpretability for a logistic regression model.
Feature interpretability in logistic regression is determined using features importance, which in this case is a Wald Chi-Squared value. The features importance in logistic regression is represented as ‘weights’ and they don’t change with each instance; i.e. weight for Customer1 and Customer2 would be the same across features/variables. For such white-box models, local and global fidelities are the same. In other words, individual predictions are explained with global explanations. Since it is straightforward to calculate the beta coefficients, it is easy to explain the outcomes.

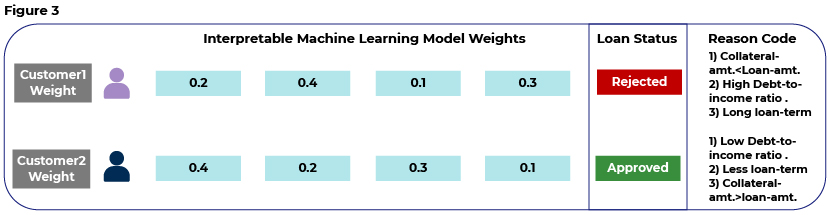
In Figure 3, we show how techniques such as Local Interpretable Model-Agnostic Explanations (LIME) and Shapley value (SHAP) explain predictions of black-box models. These techniques provide explanations of individual predictions. They also show the variables and their weights that contribute towards the prediction. For Customer1, we see in the explanation under ‘Reason Code’ that the collateral amount is lower than the loan amount. So, if the customer defaults and the bank cannot recover the loan amount, then we conclude that these indicators of collateral amount and loan amount are major contributing features towards making a prediction. Another indicator in this scenario is the debt-to-income ratio, where a higher ratio could point towards the borrowers’ inability to make regular payments.
Conclusion:
The rise of ML and Artificial Intelligence (AI) models is reinventing many aspects of financial services and, in the process, requiring explainable AI to disclose the reasoning and facts behind predictions. A black-box model provides much greater performance than a white-box model. With the help of interpretable techniques, we attempt to explain black-box model predictions to optimise the trade-off between performance and explainability. In addition, interpretable techniques provide clear interpretations and explanations of predictions based on individual instance variable weightages. LIME and SHAP are two interpretable techniques that are gaining wide acceptance in the global data science community.
Tags:
What's your view?

Thank you for sharing your Comments
Share this on


About the Author

Surbhi Badalia has six years of experience in the financial services industry. Her areas of expertise include software engineering, ETL frameworks, data science and research. At Acuity Knowledge Partners, she leads data science solutions for global banks, focusing on data framework development, features engineering, research analysis and ML algorithm development. She holds Master’s and Bachelor’s degrees in Computer Applications.
 Blog
Blog
Reignite – Preparing for a post-pandemic world....
Except for consumers, no one knows when and how the economic effects of the pandemic will ....Read More
 Blog
Blog
Future-proofing compliance professionals....
“If there’s one thing that is certain in business it is uncertainty” Stephen Covey ....Read More
Like the way we think?
Next time we post something new, we'll send it to your inbox
